Ollama & AnythingLLM 搭建 AI 知识库
1. 安装 Ollama
下载并安装:
验证安装:
ollama -v
# ollama version is 0.3.11ollama run qwen2.5:1.5b第一次运行会自动下载模型。
验证模型是否能正常运行:
ollama run qwen2.5:1.5b
# >>> who are you?
# I am Qwen, an AI language model developed by Alibaba Cloud. My purpose is to assist users in generating text for various
# tasks such as writing stories, articles, poems, emails, etc., while also providing valuable information and answering
# factual questions accurately. I aim to be a helpful assistant that can help you achieve your goals!
# >>> /bye2. AnythingLLM 安装
ll | grep AnythingLLM
# -rw-r--r--@ 1 [username] staff 305M 10 9 18:50 AnythingLLMDesktop.dmg安装完成:
3. AnythingLLM 产品概述
AnythingLLM 采用了 Javascript,前端用 React,后端用 Node.js,是一个全栈应用程序。
- 前端:
React和Vite,实现创建和管理大模型用到的知识库; - 后端:
Node.js和Express框架,实现向量数据库的管理和所有与大模型的交互; - 采集器:
Node.js和Express框架,实现对文档的处理解析;
支持多用户模式:
这一点对于企业级应用特别关键,AnythingLLM 支持多用户模式,3 种角色的权限管理。
- 系统会默认创建一个
管理员(Admin)账号,拥有全部的管理权限; - 第二种角色是
Manager账号,可管理所有工作区和文档,但是不能管理大模型、嵌入模型和向量数据库; 普通用户账号,则只能基于已授权的工作区与大模型对话,不能对工作区和系统配置做任何更改;
4. Ollama 服务器模式
Ollama 其实有两种模式:
- 聊天模式;
- 服务器模式;
这里使用服务器模式,Ollama 在后端运行大模型,开放 IP 和端口给外部软件使用。
ollama serve
# Error: listen tcp 127.0.0.1:11434: bind: address already in use通过终端或者命令行,访问 http://127.0.0.1:11434 进行验证:
curl http://127.0.0.1:11434
# Ollama is runningOllama is running 输出,表示 Ollama 正在运行。
5. 启动并配置 AnythingLLM
搭建一个本地知识库,会涉及到三个关键:
LLM Model,大语言模型。它负责处理和理解自然语言。Embedding Model,嵌入模型。它负责把高维度的数据转化为低维度的嵌入空间。这个数据处理过程在RAG中非常重要。Vector Store,向量数据库,专门用来高效处理大规模向量数据。
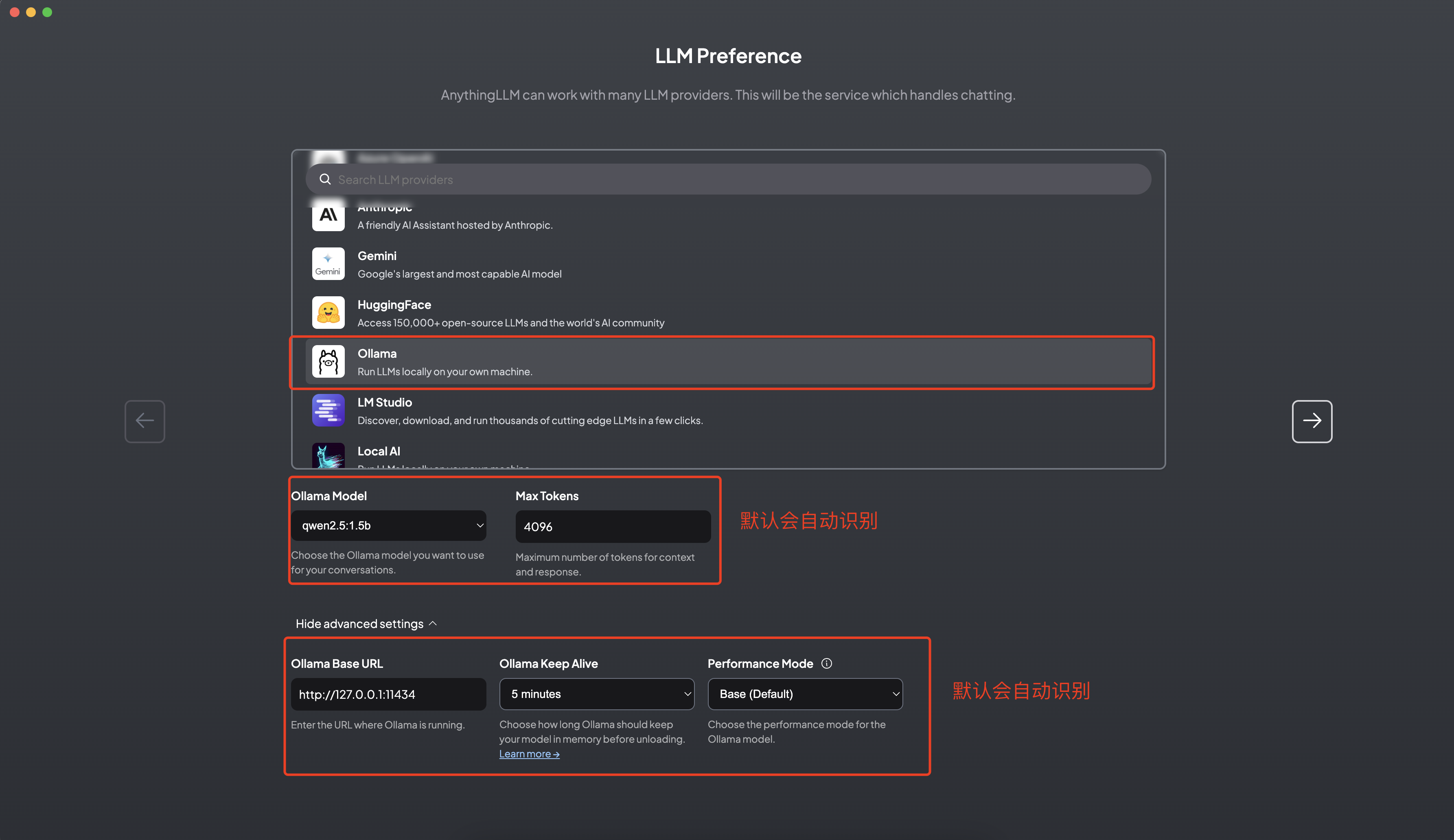
5.1 本地大模型选择
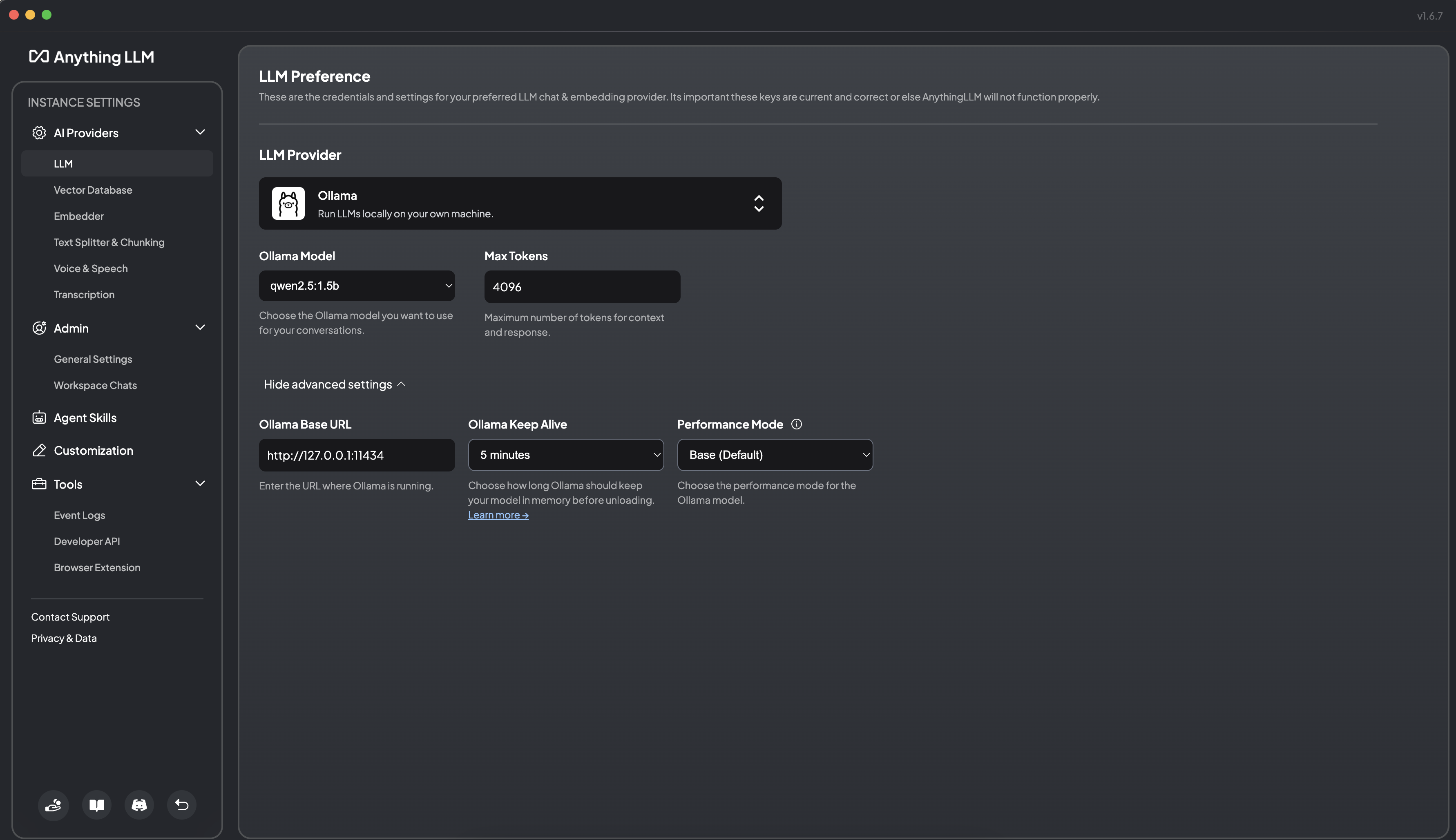
选择 Ollama,填入 Ollama 的 http://127.0.0.1:11434 端口,然后选择你下载的模型。 当然你也可以使用 OpenAI,使用更强大的云端模型,提供基础模型支持。但这样的话,就不是完全本地化的私有部署了。
接下来,AnythingLLM 会默认使用自带的嵌入模型 AnythingLLMEmbedder 和 内置的向量数据库 LanceDB:

接下来进入交互界面:
可以通过 Settings 来进行个性化设置:
可以对大模型进行修改:
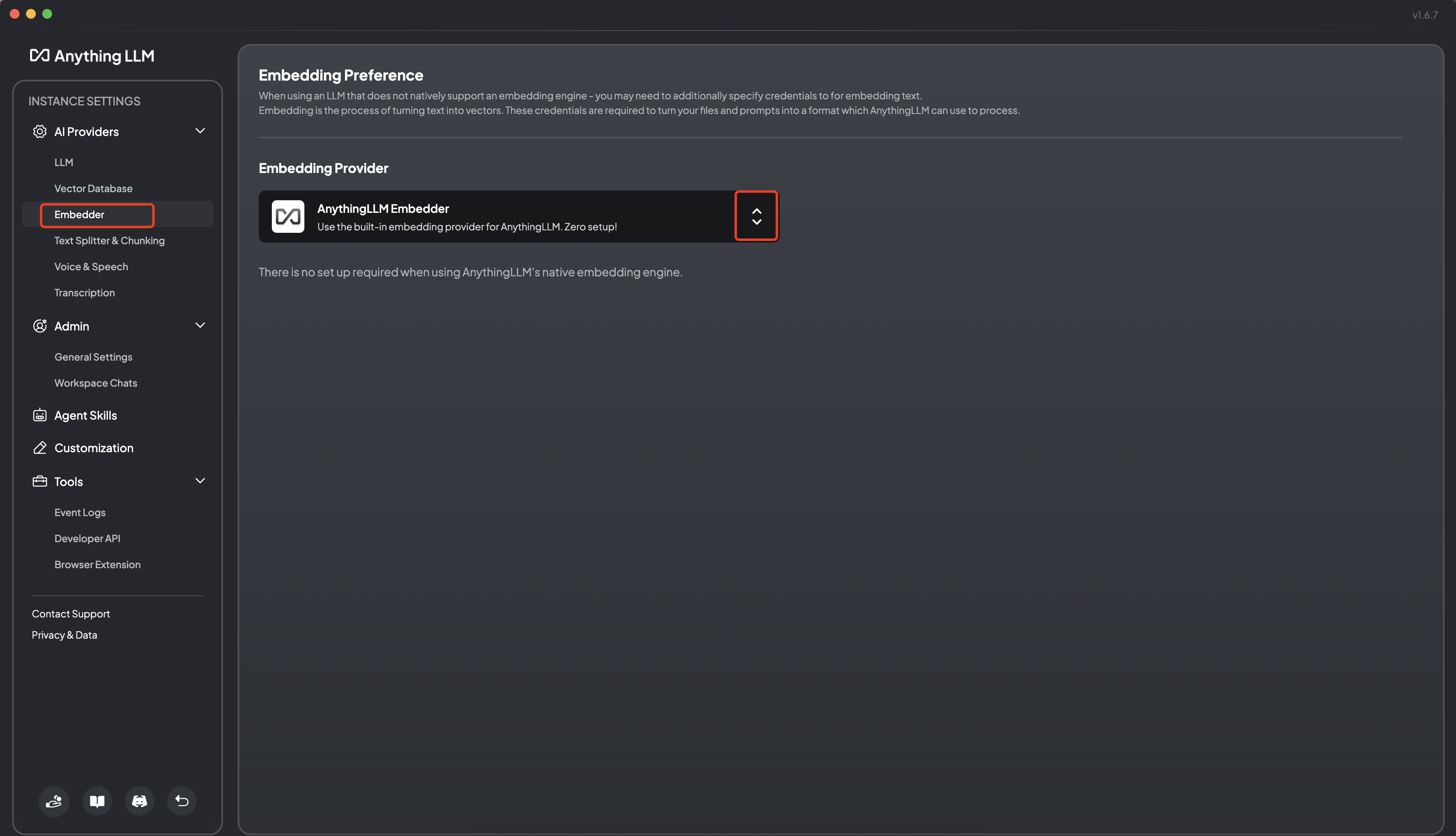
5.2 Embedding 配置
可以选择:
- nomic-embed-text;
AnythingLLM自带的AnythingLLMEmbedder;
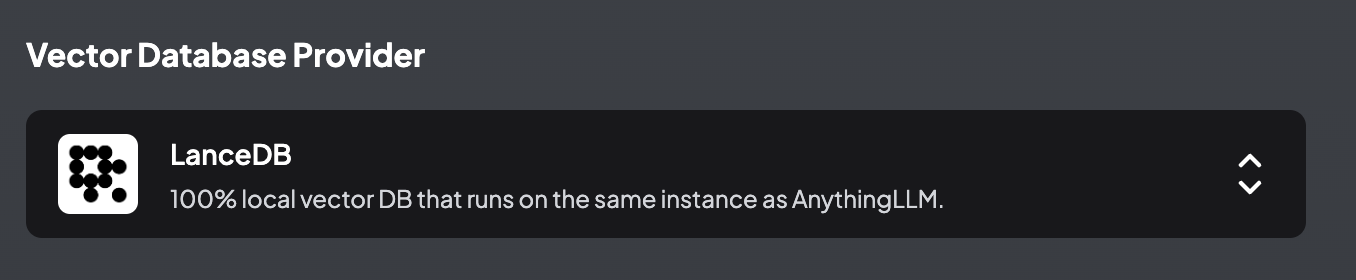
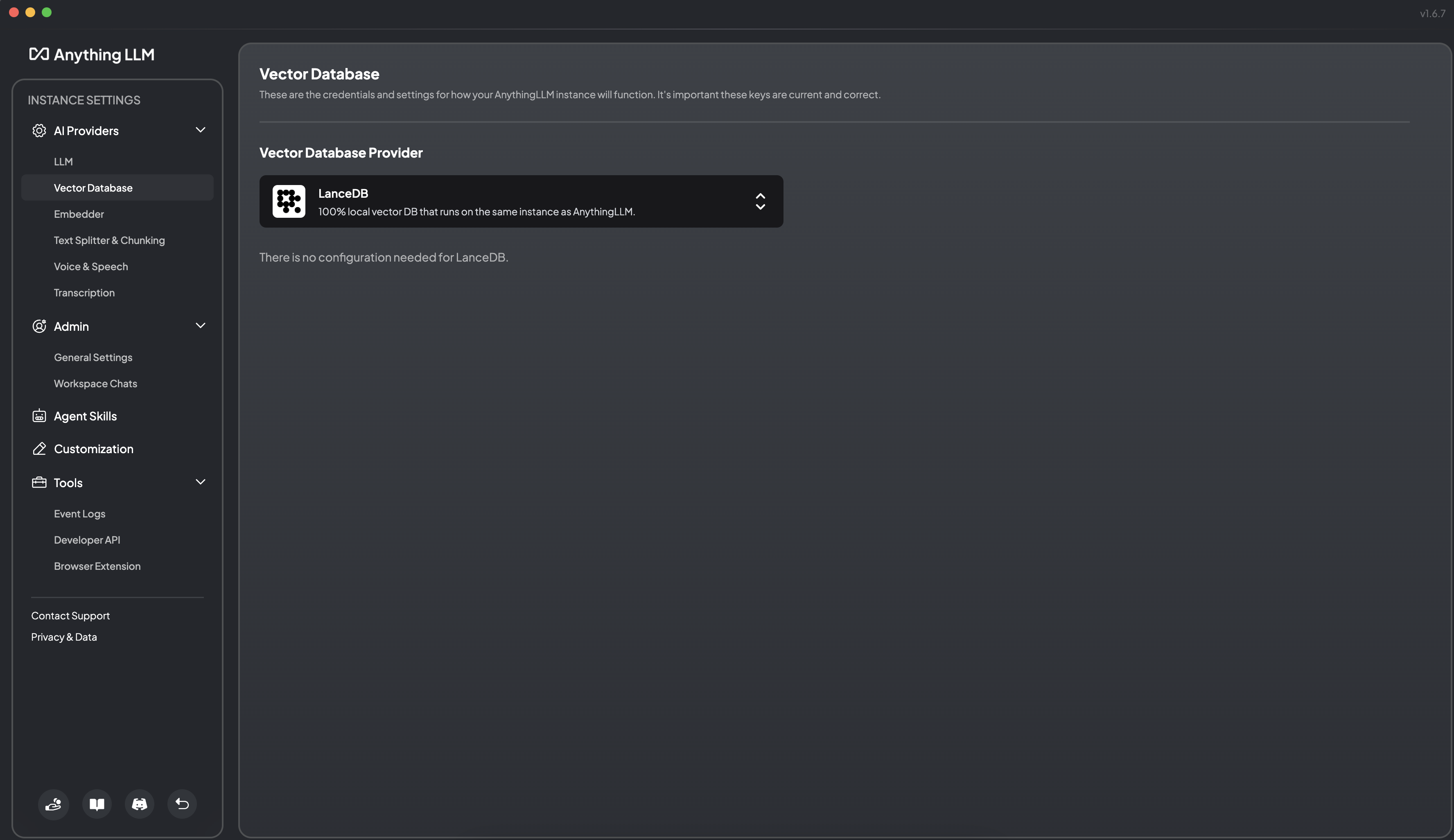
5.3 Vector Database 配置
AnythingLLM 默认使用内置的向量数据库 LanceDB。 这是一款无服务器向量数据库,可嵌入到应用程序中,支持向量搜索、全文搜索和 SQL。 我们也可以选择:
等向量数据库。
6. AnythingLLM 文档嵌入
6.1 新建工作区
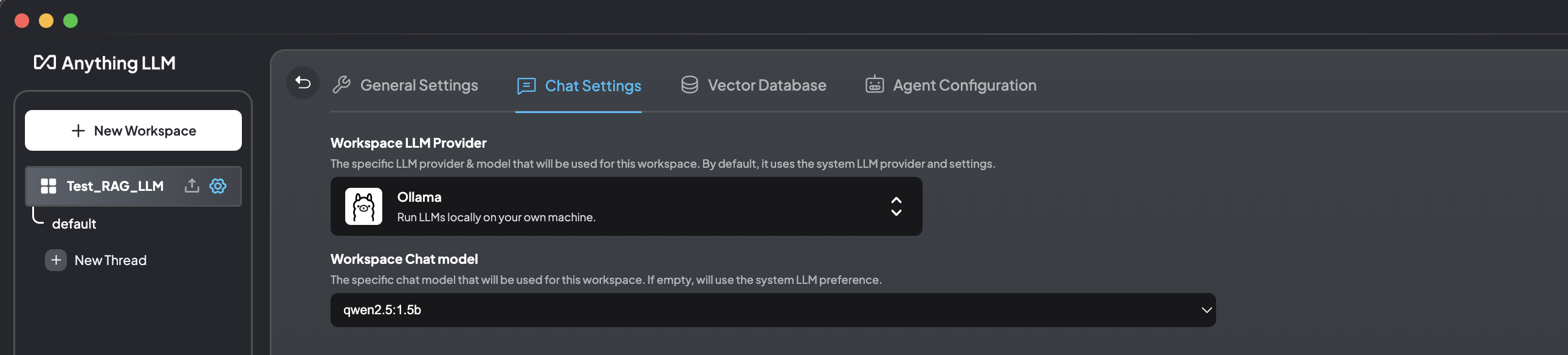
工作区设置大模型:
6.2 工作区共享文档
AnythingLLM 可以支持 PDF、TXT、DOCX 等文档,可以提取文档中的文本信息,经过嵌入模型(Embedding Models),保存在向量数据库中,并通过一个简单的 UI 界面管理这些文档。
为管理这些文档,AnythingLLM 引入工作区(Workspace)的概念,作为文档的容器,可以在一个工作区内共享文档,但是工作区之间隔离。
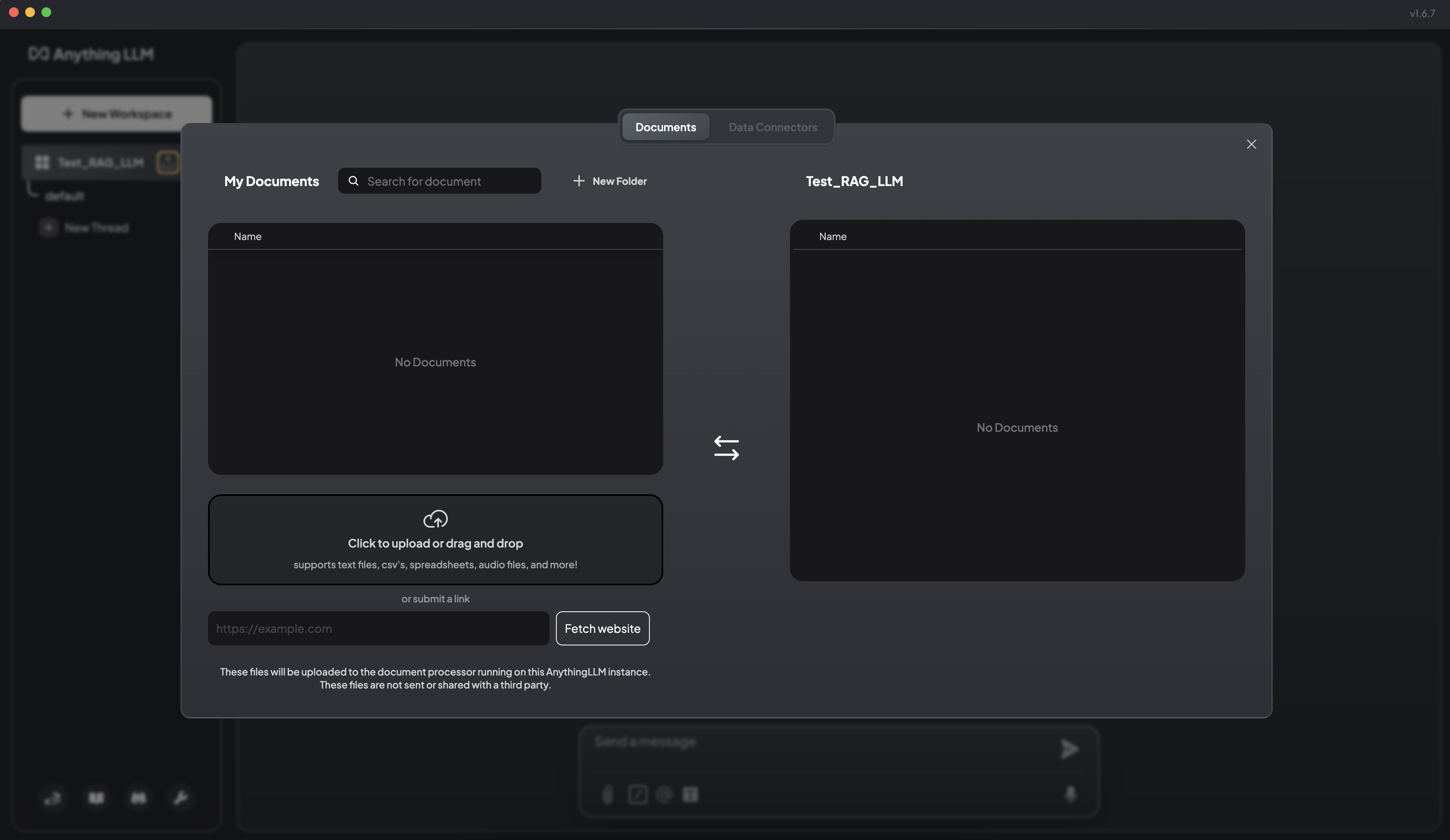
AnythingLLM 既可以上传文档,也可以抓取网页信息。
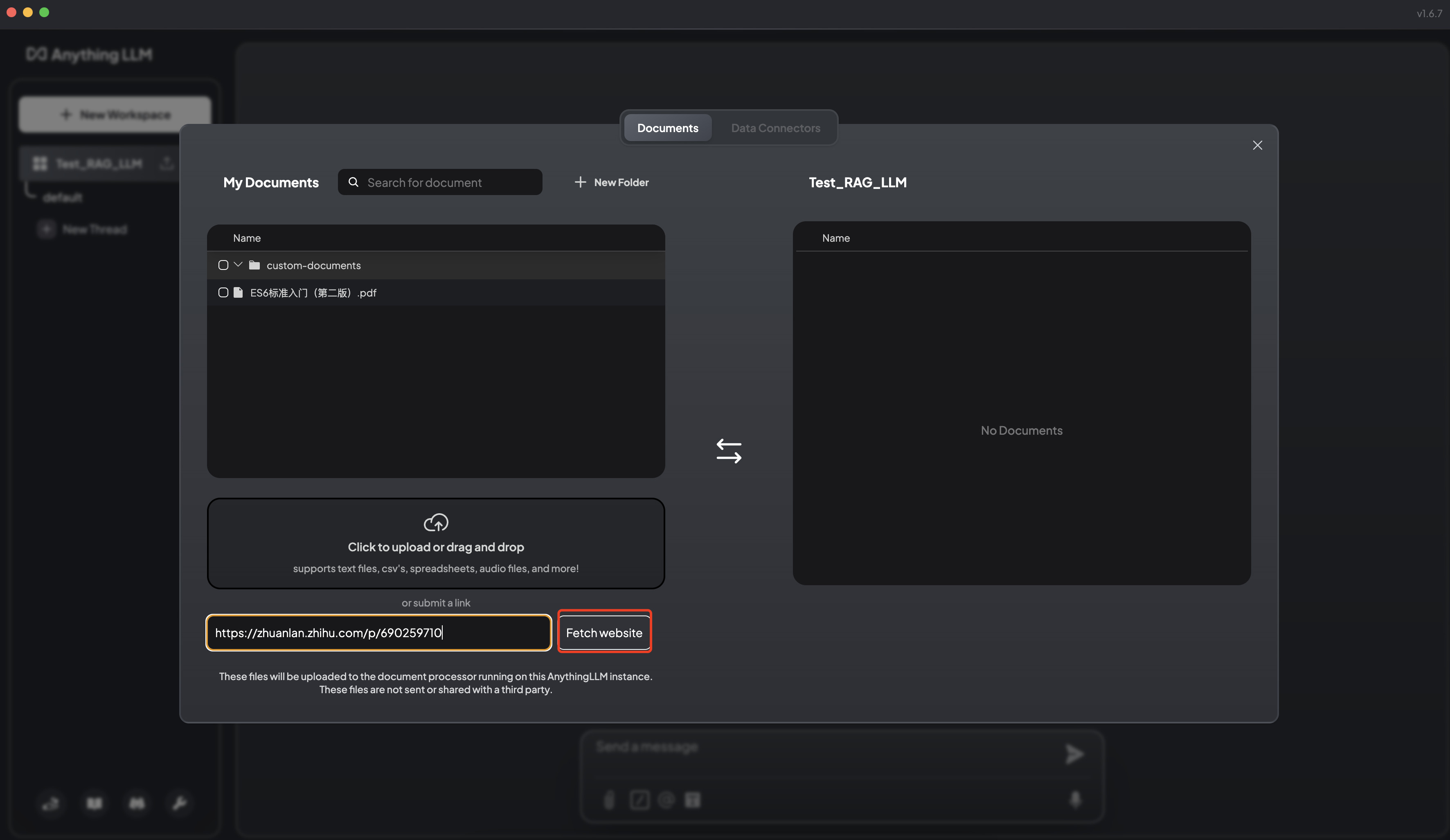
抓取网页 如何在前端渲染数学公式?:
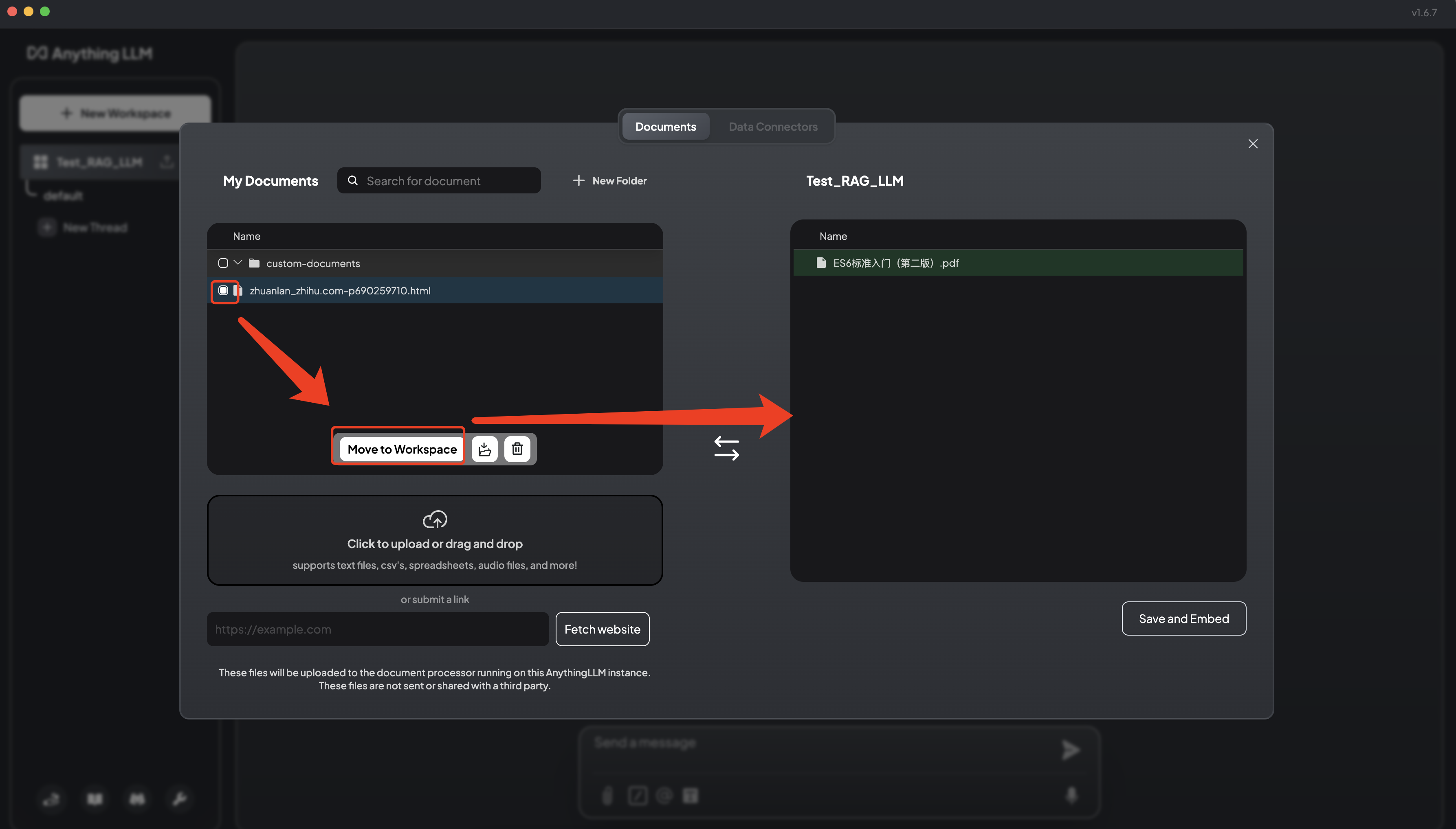
6.4 将文档保存嵌入工作区向量数据库
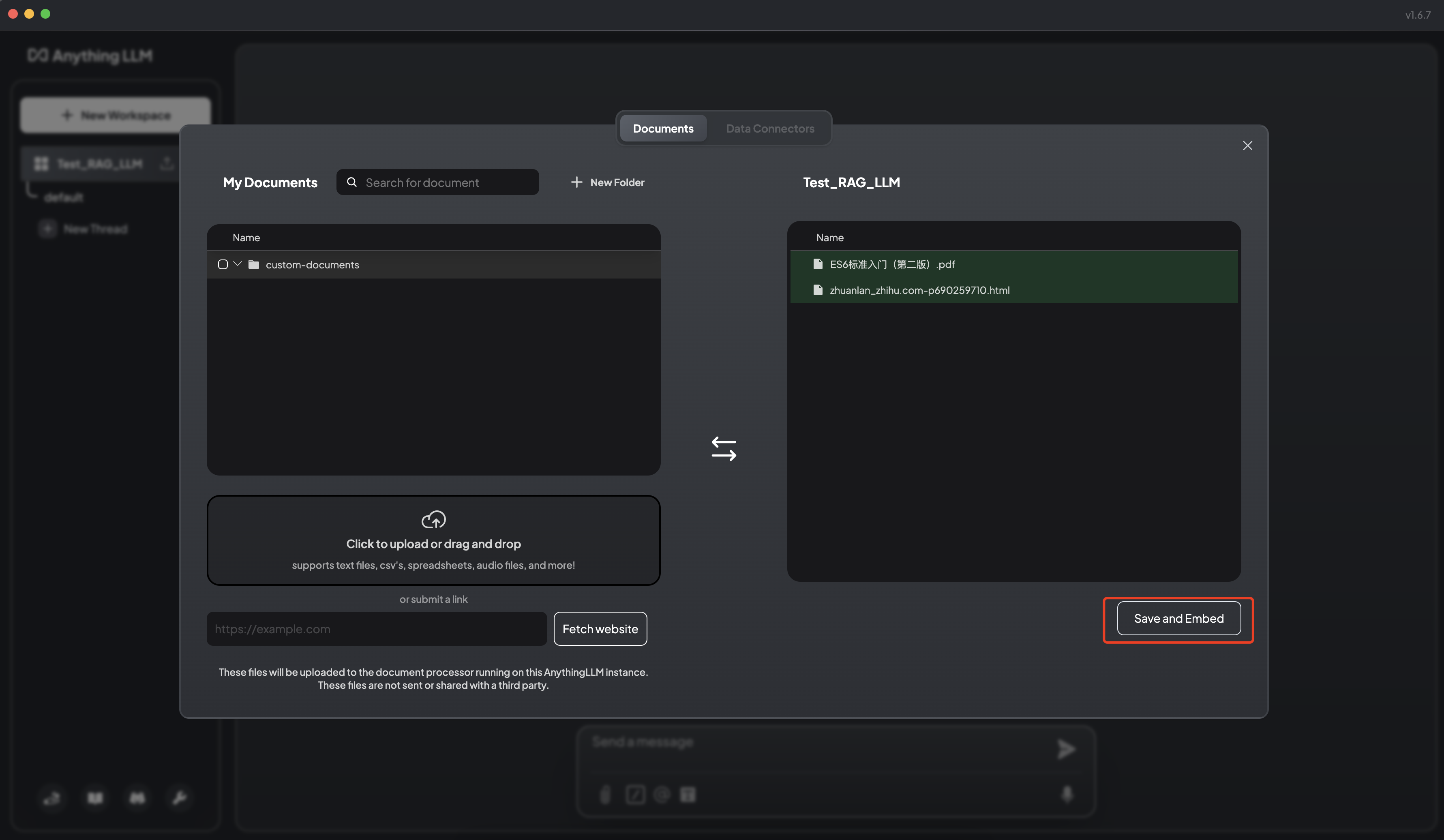
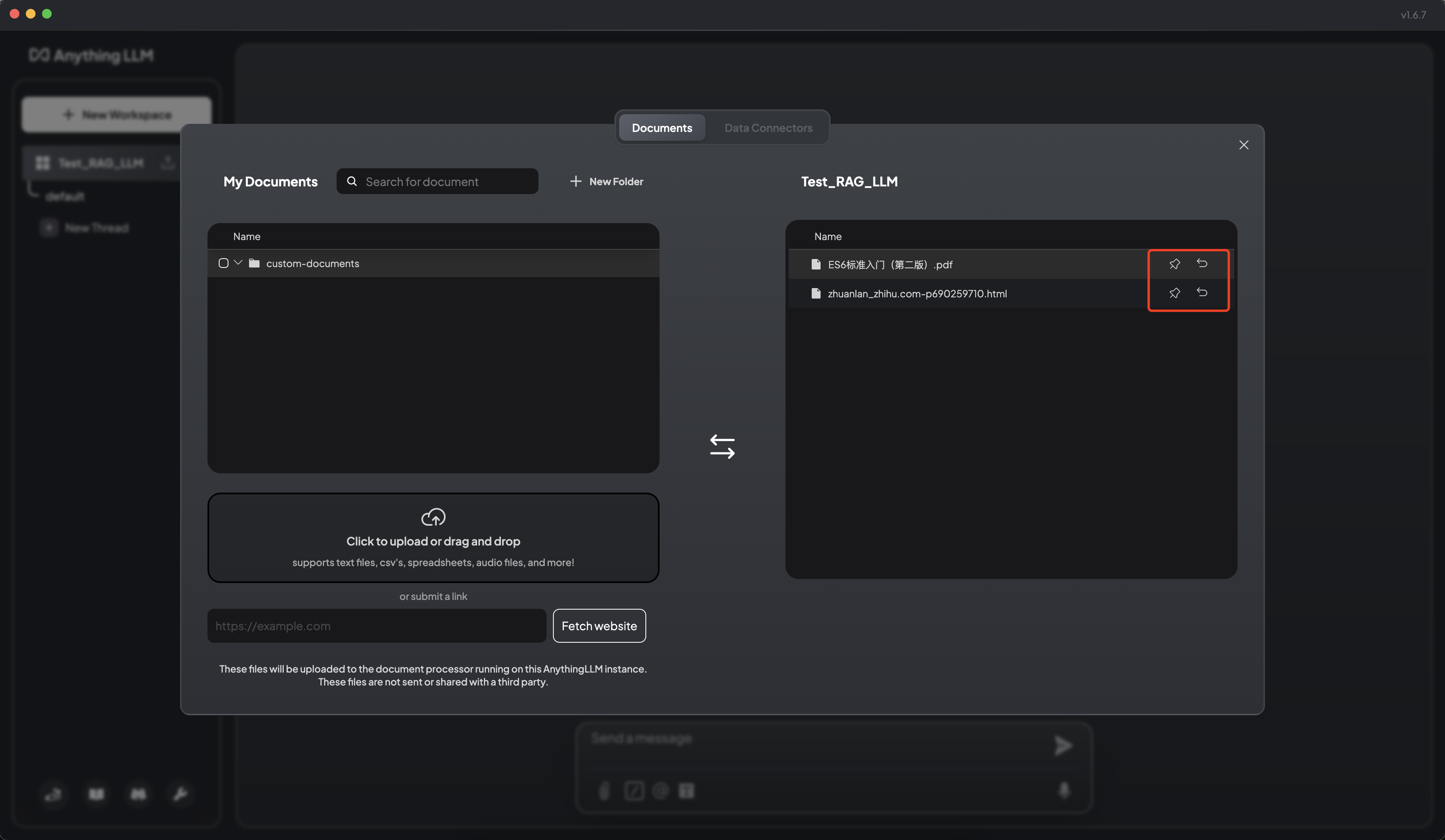
根据知识库中上传的文档,进行知识问答。
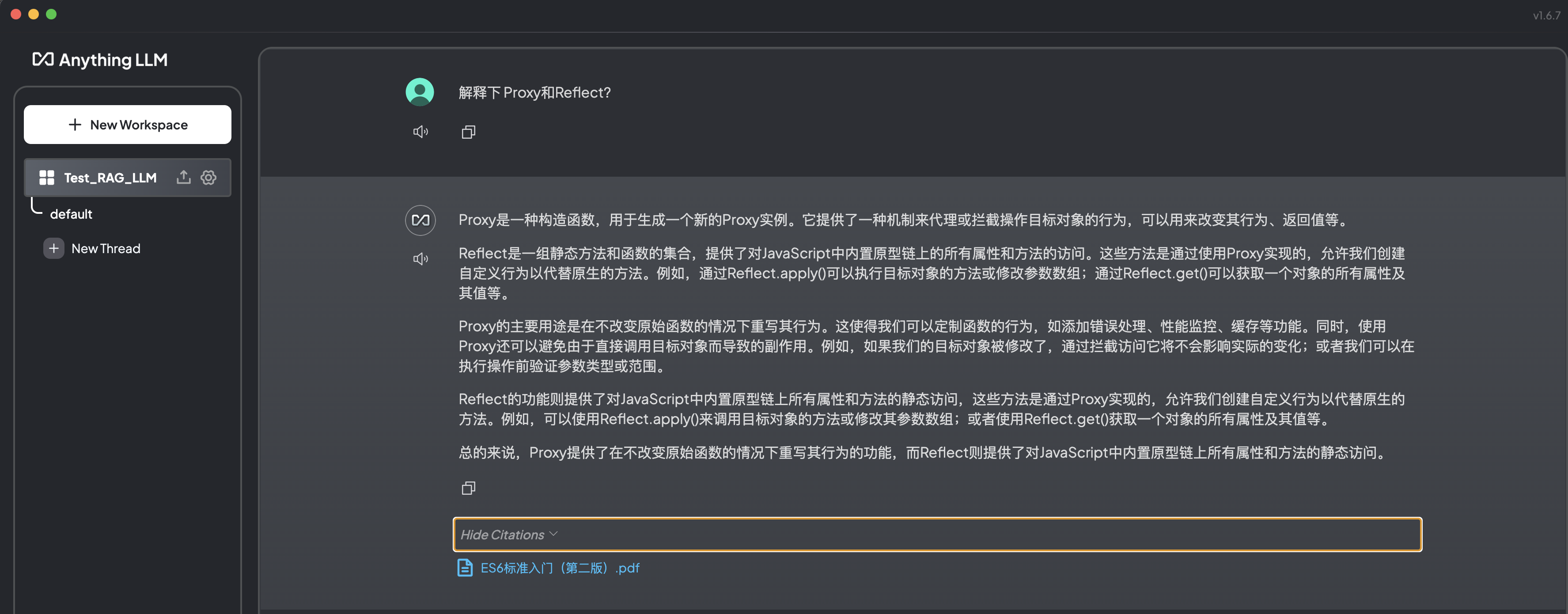
7. RAG 智能问答
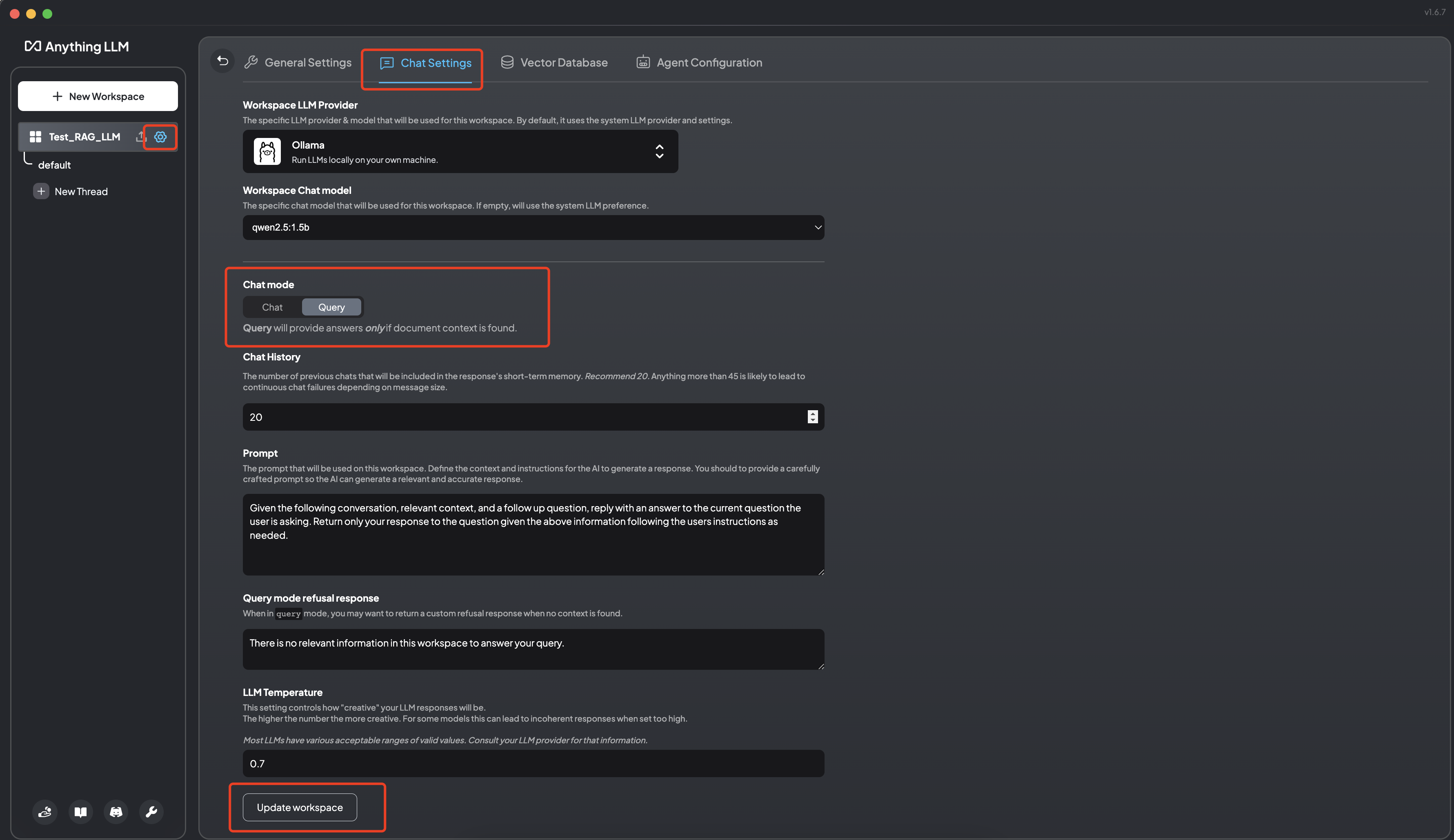
点击空间的设置按钮并切换为 Query 状态后,模型将仅在找到文档上下文时提供答案(回答会更加绑定于知识库)。
文档匹配(工作区用的是默认的 LLM 大模型):
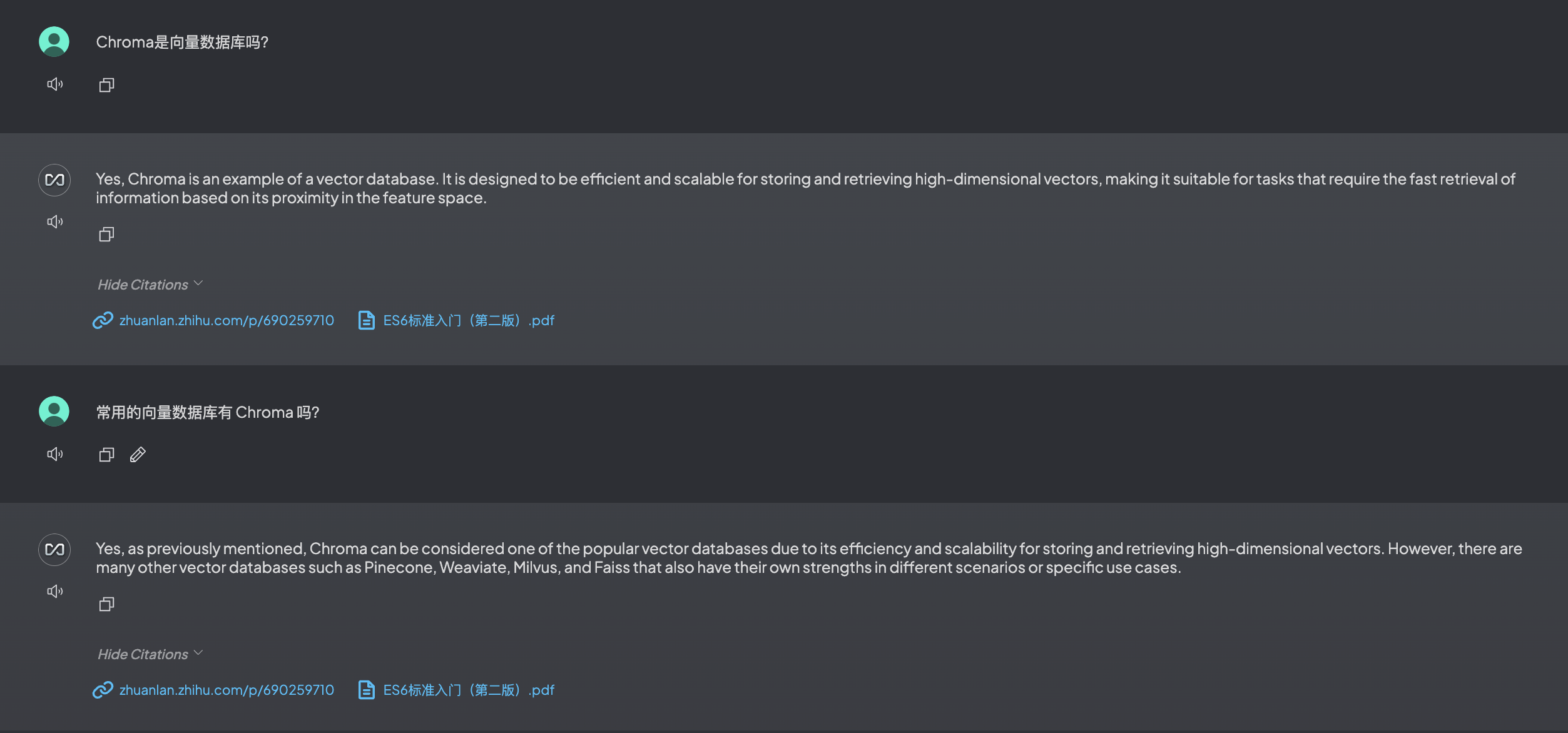
可以发现默认的大模型对中文的支持不是很好且响应速度也比较慢。
文档不匹配(工作区切换为 Ollama 的本地大模型 qwen2.5:1.5b):
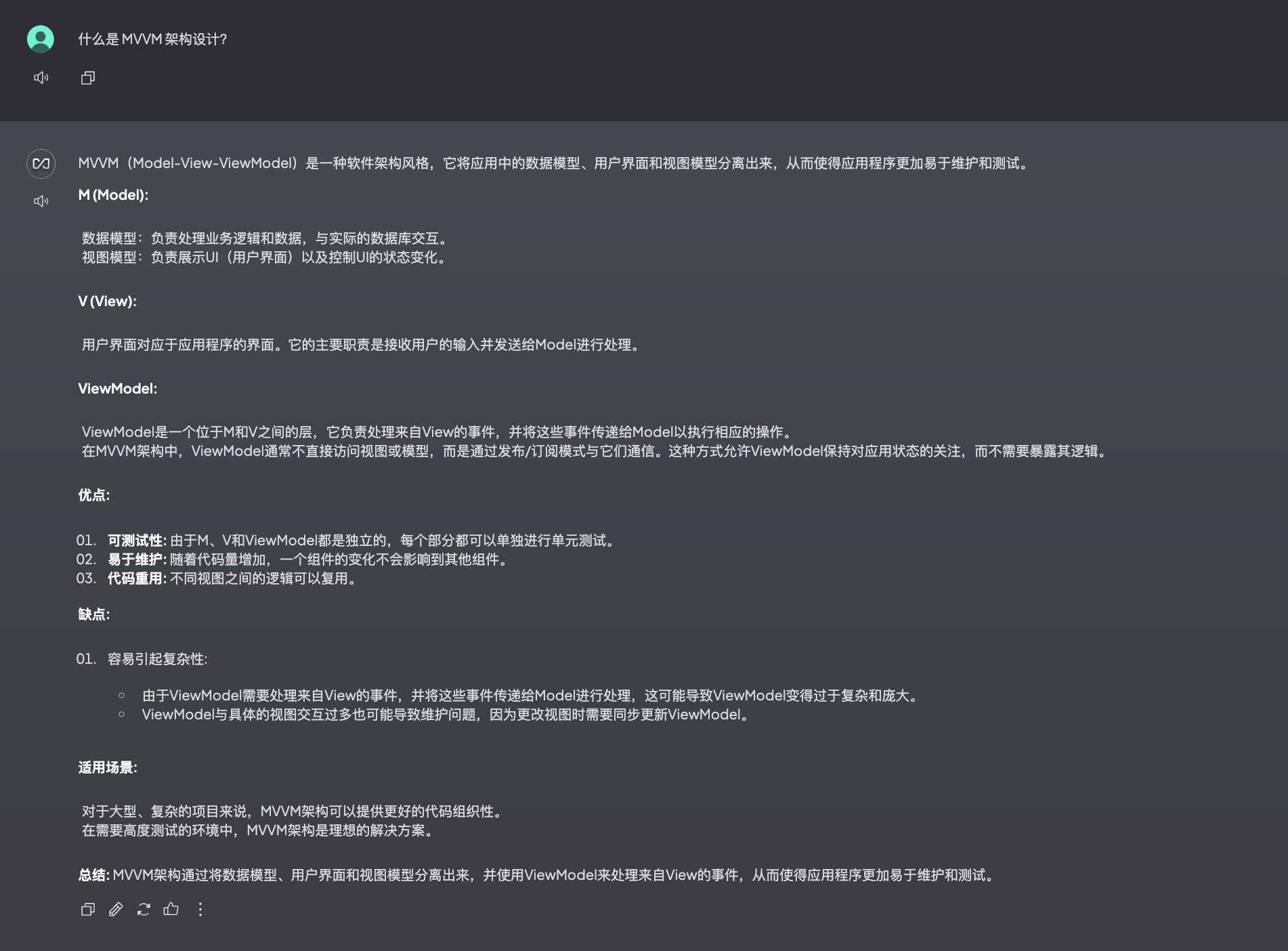
8. API 服务
8.1 生成 API 私钥
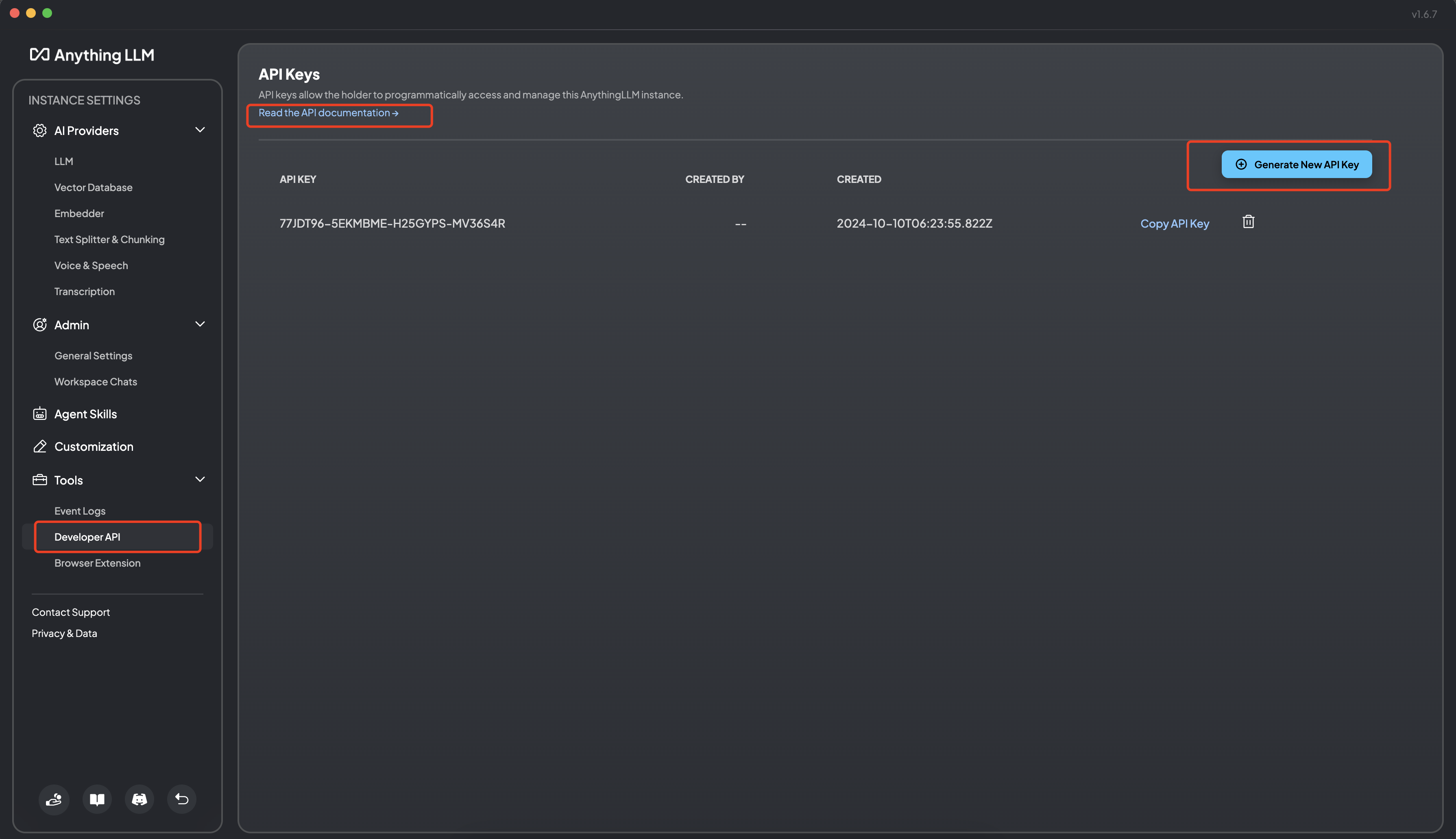
8.2 调试验证
可以通过 Web 访问接口文档:
http://localhost:3001/api/docs/也可以通过客户端访问接口文档:
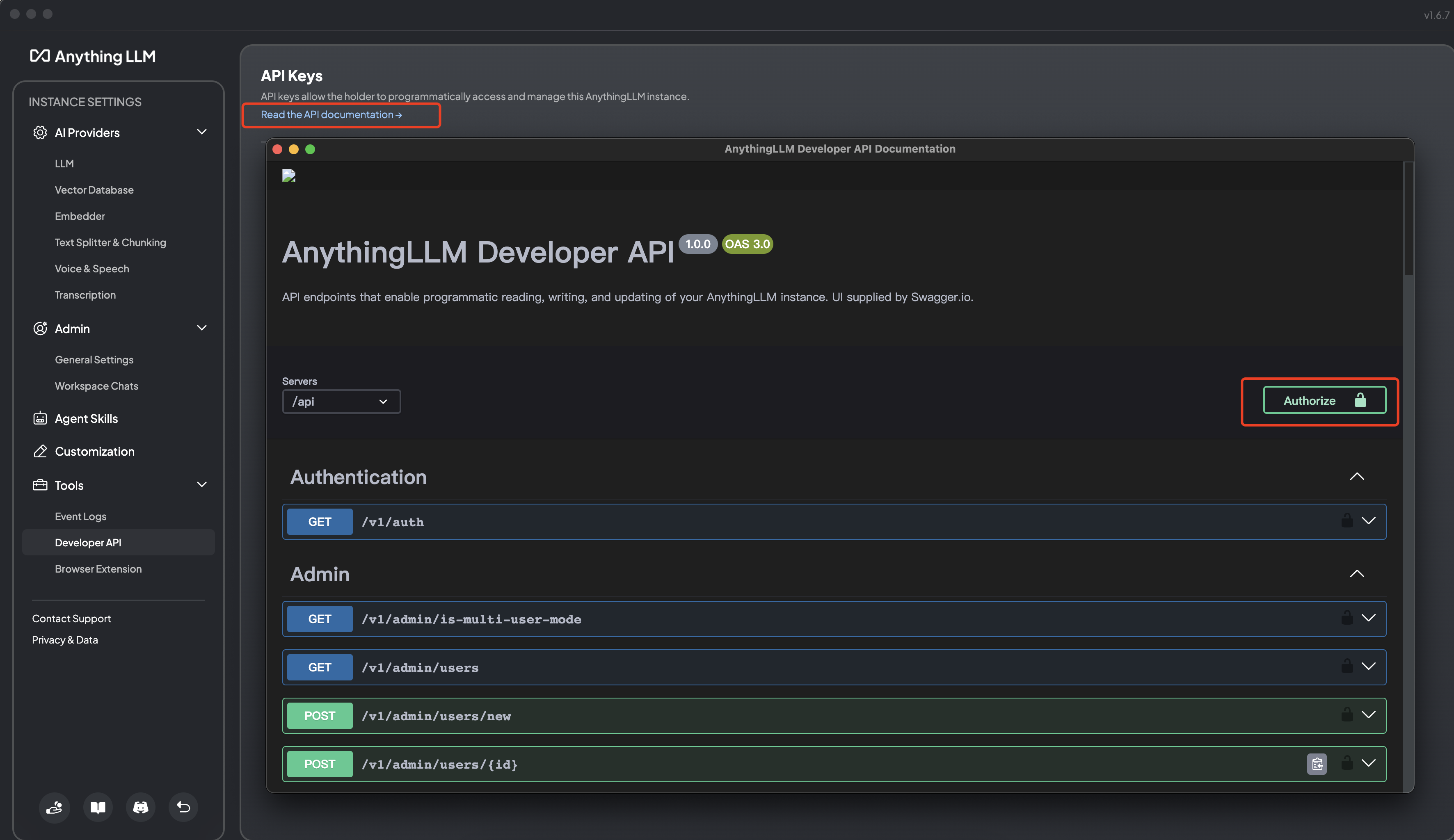
设置 API 访问授权密码:
接口调试:
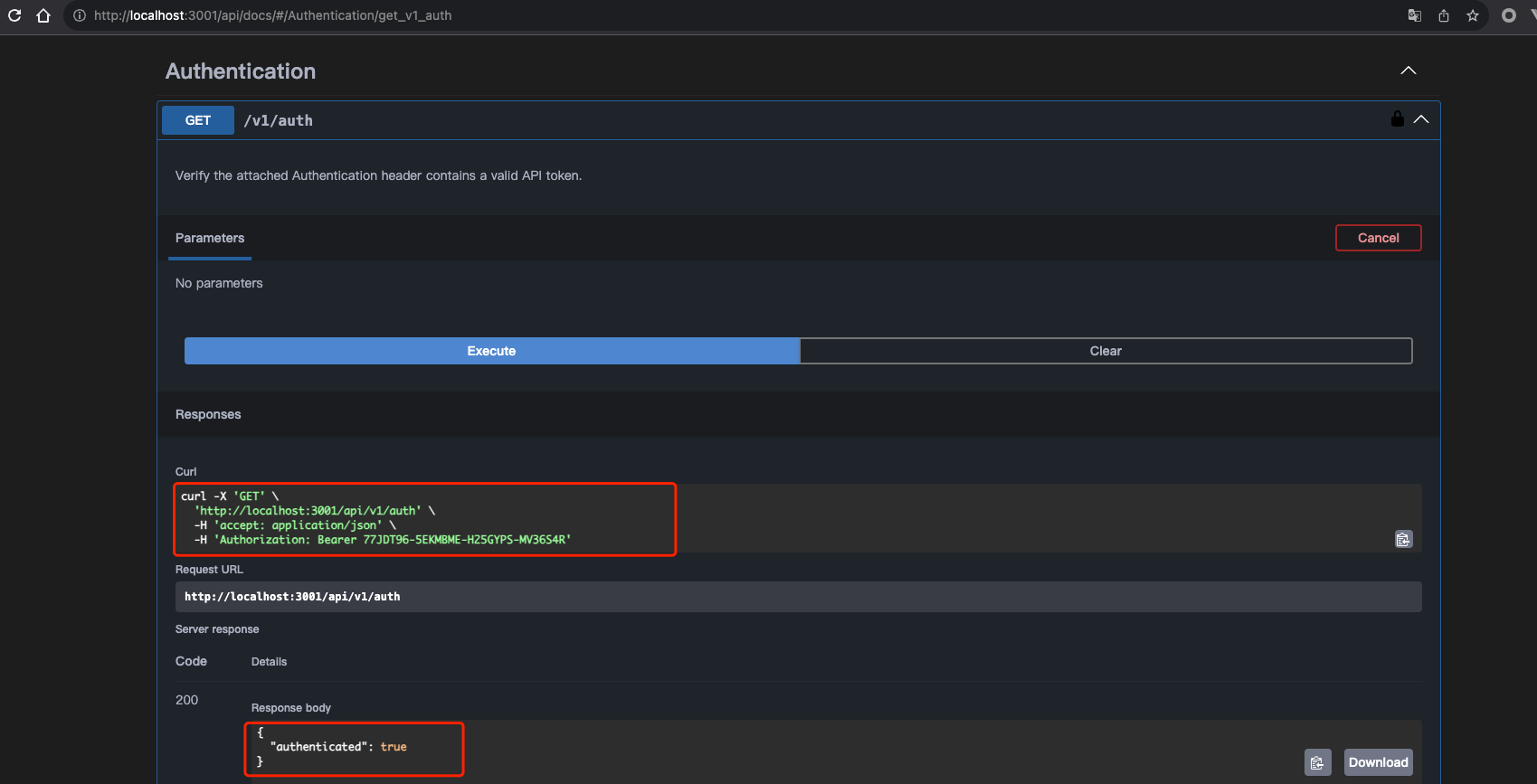
命令行调用:
curl -X 'GET' \
'http://localhost:3001/api/v1/auth' \
-H 'accept: application/json' \
-H 'Authorization: Bearer 77JDT96-5EKMBME-H25GYPS-MV36S4R'
# {"authenticated":true}