为什么数据库字段建议使用 NOT NULL?
一、前言
基于目前大部分的开发现状来说,我们都会把字段全部设置成 NOT NULL 并且给默认值的形式。
通常,对于默认值一般这样设置:
- 整形,我们一般使用
0作为默认值。 - 字符串,默认空字符串
- 时间,可以默认
1970-01-01 08:00:01, 或者默认0000-00-00 00:00:00, 但是连接参数要添加zeroDateTimeBehavior=convertToNull, 建议的话还是不要用这种默认的时间格式比较好
但是,考虑下原因,为什么要设置成 NOT NULL?
来自高性能 Mysql 中有这样一段话:
尽量避免
NULL很多表都包含可为
NULL(空值)的列,即使应用程序并不需要保存NULL也是如此,这是因为可为NULL是列的默认属性。通常情况下最好指定列为NOT NULL, 除非真的需要存储NULL值。如果查询中包含可为
NULL的列,对MySql来说更难优化,因为可为NULL的列使得索引、索引统计和值比较都更复杂。
- 可为
NULL的列会使用更多的存储空间,在MySql里也需要特殊处理。- 当可为
NULL的列被索引时,每个索引记录需要一个额外的字节,在MyISAM里甚至还可能导致固定大小的索引(例如只有一个整数列的索引)变成可变大小的索引。通常把可为
NULL的列改为NOT NULL带来的性能提升比较小,所以(调优时)没有必要首先在现有schema中查找并修改掉这种情况,除非确定这会导致问题。但是,如果计划在列上建索引,就应该尽量避免设计成可为NULL的列。当然也有例外,例如值得一提的是,
InnoDB使用单独的位(bit)存储NULL值,所以对于稀疏数据有很好的空间效率。但这一点不适用于MyISAM。
书中的描述说了几个主要问题,这里暂且抛开 MyISAM 的问题不谈,这里针对 InnoDB 作为考量条件。
- 如果不设置
NOT NULL的话,NULL是列的默认值,如果不是本身需要的话,尽量就不要使用NULL - 使用
NULL带来更多的问题,比如索引、索引统计、值计算更加复杂,如果使用索引,就要避免列设置成NULL - 如果是索引列,会带来的存储空间的问题,需要额外的特殊处理,还会导致更多的存储空间占用
- 对于稀疏数据有更好的空间效率,稀疏数据指的是很多值为
NULL, 只有少数行的列有非NULL值的情况
二、数据准备
2.1 Mysql 安装
这里采用 docker 安装。
2.2 建库建表
因为要用实际的
mysql表数据进行测试,所以这里先做下基础设施的搭建。
# mysql>
# 创建测试数据库
CREATE DATABASE IF NOT EXISTS `d_test`;
# 创建测试表
CREATE TABLE IF NOT EXISTS `t_test` (
`FuiId` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`FstrName` varchar(255) DEFAULT NULL COMMENT '名字',
`FuiAge` int(11) DEFAULT NULL COMMENT '年龄',
`FuiCreateTime` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`FuiId`),
KEY `idx_name` (`FstrName`),
KEY `idx_age` (`FuiAge`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;注:这里命名规范:
- 数据库名以
d_作为前缀,表示database- 表名以
t_作为前缀,表示table- 表字段命名:
第一个字母
F代表字段Field;第二个字母
ui代表无符号整数类型unsigned integerstr代表字符串类型string
2.3 数据库连接
测试数据库连接:
mysql -h 127.0.0.1 -u root -p
# Enter password:
# Welcome to the MySQL monitor. Commands end with ; or \g.
# Your MySQL connection id is 11
# Server version: 5.7.32 MySQL Community Server (GPL)
# Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
# Oracle is a registered trademark of Oracle Corporation and/or its
# affiliates. Other names may be trademarks of their respective
# owners.
# Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
# mysql>继续执行:
-- mysql>
use d_test;
-- Reading table information for completion of table and column names
-- You can turn off this feature to get a quicker startup with -A
-- Database changed我们插入几条数据作为测试数据:
-- mysql>
INSERT INTO `t_test` (`FuiId`, `FstrName`, `FuiAge`)
VALUES
(1, 'test', 10),
(2, NULL, NULL),
(3, NULL, 12);查看下执行结果:
-- mysql>
select * from t_test;
-- +-------+----------+--------+---------------------+
-- | FuiId | FstrName | FuiAge | FuiCreateTime |
-- +-------+----------+--------+---------------------+
-- | 1 | test | 10 | 2021-04-13 12:08:00 |
-- | 2 | NULL | NULL | 2021-04-13 12:08:00 |
-- | 3 | NULL | 12 | 2021-04-13 12:08:00 |
-- +-------+----------+--------+---------------------+
-- 3 rows in set (0.00 sec)我们从以下几方面分别说明:
三、默认值
对于 MySql 而言,如果不主动设置为 NOT NULL 的话,那么插入数据的时候默认值就是 NULL。
NULL 和 NOT NULL 使用的空值代表的含义是不一样, NULL 可以认为这一列的值是未知的,空值则可以认为我们知道这个值,只不过他是空的而已。
举个例子,一张表中的某一条
name字段是NULL, 我们可以认为不知道名字是什么,反之如果是空字符串则可以认为我们知道没有名字,他就是一个空值。
而对于大多数程序的情况而言,没有什么特殊需要非要字段要 NULL 的吧, NULL 值反而会对程序造成比如空指针的问题。
四、值计算
聚合函数不准确
对于 NULL 值的列,使用聚合函数的时候会忽略 NULL 值。
现在我们有一张表 t_test, FstrName 字段默认是 NULL, 此时对 FstrName 进行 count 得出的结果是 1, 这个是错误的。
count(*) 是对表中的行数进行统计,count(FstrName) 则是对表中非 NULL 的列进行统计。
-- mysql>
select count(*),count(1),count(FuiId),count(FstrName),count(FuiAge) from t_test;
-- +----------+----------+--------------+-----------------+---------------+
-- | count(*) | count(1) | count(FuiId) | count(FstrName) | count(FuiAge) |
-- +----------+----------+--------------+-----------------+---------------+
-- | 3 | 3 | 3 | 1 | 2 |
-- +----------+----------+--------------+-----------------+---------------+
-- 1 row in set (0.00 sec)=失效
对于 NULL 值的列,是不能使用 = 表达式进行判断的,下面对 FstrName 的查询是不成立的,必须使用 is NULL。
-- mysql>
select * from t_test where FstrName = NULL;
-- Empty set (0.00 sec)
select * from t_test where FstrName IS NULL;
-- +-------+----------+--------+---------------------+
-- | FuiId | FstrName | FuiAge | FuiCreateTime |
-- +-------+----------+--------+---------------------+
-- | 2 | NULL | NULL | 2021-04-13 12:08:00 |
-- | 3 | NULL | 12 | 2021-04-13 12:08:00 |
-- +-------+----------+--------+---------------------+
-- 2 rows in set (0.00 sec)与其他值运算
NULL 和 其他任何值进行运算 都是 NULL, 包括表达式的值也是 NULL。
t_test 表第二条记录 FuiAge 是 NULL,所以 +1 之后还是 NULL, FstrName 是 NULL, 进行 concat 运算之后结果还是 NULL。
-- mysql>
select FuiAge+1, concat(FstrName, NULL) from t_test;
-- +----------+------------------------+
-- | FuiAge+1 | concat(FstrName, NULL) |
-- +----------+------------------------+
-- | 11 | NULL |
-- | NULL | NULL |
-- | 13 | NULL |
-- +----------+------------------------+
-- 3 rows in set (0.00 sec)可以再看下下面的例子,任何和 NULL 进行运算的话得出的结果都会是 NULL, 想象下你设计的某个字段如果是 NULL 还不小心进行各种运算,最后得出的结果 @_@.
-- mysql>
select 1 IS NULL, 1 IS NOT NULL, 1 = NULL, 1<> NULL, 1 < NULL, 1 > NULL;
-- +-----------+---------------+----------+----------+----------+----------+
-- | 1 IS NULL | 1 IS NOT NULL | 1 = NULL | 1<> NULL | 1 < NULL | 1 > NULL |
-- +-----------+---------------+----------+----------+----------+----------+
-- | 0 | 1 | NULL | NULL | NULL | NULL |
-- +-----------+---------------+----------+----------+----------+----------+
-- 1 row in set (0.00 sec)distinct、group by、order by
对于distinct和group by来说,所有的 NULL 值都会被视为相等,对于 order by 来说升序 NULL 会排在最前
-- mysql>
select FstrName from t_test group by FstrName;
-- +----------+
-- | FstrName |
-- +----------+
-- | NULL |
-- | test |
-- +----------+
-- 2 rows in set (0.01 sec)
select distinct(FstrName) from t_test;
-- +----------+
-- | FstrName |
-- +----------+
-- | test |
-- | NULL |
-- +----------+
-- 2 rows in set (0.00 sec)
select * from t_test order by FstrName;
-- +-------+----------+--------+---------------------+
-- | FuiId | FstrName | FuiAge | FuiCreateTime |
-- +-------+----------+--------+---------------------+
-- | 2 | NULL | NULL | 2021-04-13 12:08:00 |
-- | 3 | NULL | 12 | 2021-04-13 12:08:00 |
-- | 1 | test | 10 | 2021-04-13 12:08:00 |
-- +-------+----------+--------+---------------------+
-- 3 rows in set (0.00 sec)其他问题
表中只有一条有名字(即 FstrName 字段不为空)的记录,此时查询名字 !=test 预期的结果应该是想查出来剩余的两条记录,会发现与预期结果不匹配。
-- mysql>
select * from t_test where FstrName != 'test';
-- Empty set (0.00 sec)五、索引问题
为了验证 NULL 字段对索引的影响,分别对 FstrName 和 FuiAge 添加索引。
-- mysql>
show create table t_test;
-- +--------+-------------------------------------------+
-- | Table | CreateTable |
-- +--------+-------------------------------------------+
-- | t_test | CREATE TABLE `t_test` (
-- `FuiId` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
-- `FstrName` varchar(255) DEFAULT NULL COMMENT '名字',
-- `FuiAge` int(11) DEFAULT NULL COMMENT '年龄',
-- `FuiCreateTime` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
-- PRIMARY KEY (`FuiId`),
-- KEY `idx_name` (`FstrName`),
-- KEY `idx_age` (`FuiAge`)
-- ) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8 |
-- +---------+-------------------------------------------+
-- 1 row in set (0.00 sec)数据量少的情况下,使用 IS NULL和范围查询都是可以正常使用索引的,看以下例子:
-- mysql>
explain select * from t_test where FstrName <=> NULL;
-- +----+-------------+--------+------------+------+---------------+----------+---------+-------+------+----------+-----------------------+
-- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
-- +----+-------------+--------+------------+------+---------------+----------+---------+-------+------+----------+-----------------------+
-- | 1 | SIMPLE | t_test | NULL | ref | idx_name | idx_name | 153 | const | 2 | 100.00 | Using index condition |
-- +----+-------------+--------+------------+------+---------------+----------+---------+-------+------+----------+-----------------------+
-- 1 row in set, 1 warning (0.00 sec)
explain select * from t_test where FuiAge > 10;
-- +----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
-- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
-- +----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
-- | 1 | SIMPLE | t_test | NULL | range | idx_age | idx_age | 5 | NULL | 1 | 100.00 | Using index condition |
-- +----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
-- 1 row in set, 1 warning (0.00 sec)然后接着我们往数据库中继续插入一些数据进行测试,当 NULL 列值变多之后发现索引失效了。
-- mysql>
select * from t_test;
-- +-------+----------+--------+---------------------+
-- | FuiId | FstrName | FuiAge | FuiCreateTime |
-- +-------+----------+--------+---------------------+
-- | 1 | test | 10 | 2021-04-13 12:08:00 |
-- | 2 | NULL | NULL | 2021-04-13 12:08:00 |
-- | 3 | NULL | 12 | 2021-04-13 12:08:00 |
-- | 4 | NULL | NULL | 2021-04-13 13:04:56 |
-- | 5 | NULL | NULL | 2021-04-13 13:04:58 |
-- | 6 | NULL | NULL | 2021-04-13 13:05:00 |
-- +-------+----------+--------+---------------------+
-- 6 rows in set (0.01 sec)
explain select * from t_test where FstrName <=> NULL;
-- +----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
-- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
-- +----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
-- | 1 | SIMPLE | t_test | NULL | ALL | idx_name | NULL | NULL | NULL | 6 | 83.33 | Using where |
-- +----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
-- 1 row in set, 1 warning (0.00 sec)我们知道,一个 查询 SQL 执行大概是这样的流程:
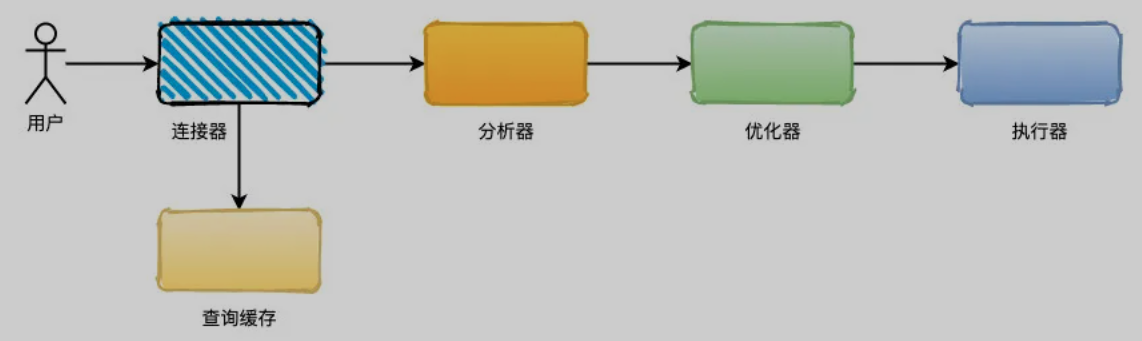
首先 连接器 负责连接到指定的数据库上,接着看看 查询缓存 中是否有这条语句,如果有就直接返回结果。
如果缓存没有命中的话,就需要 分析器 来对 SQL 语句进行 语法和词法 分析,判断 SQL 语句 是否合法。
然后来到 优化器,就会选择 使用什么索引 比较合理, SQL 语句具体怎么执行的方案就确定下来了。
最后 执行器 负责执行语句、有无权限进行查询,返回执行结果。
注:从上面的简单测试结果其实可以看到,
索引列存在 NULL就会导致优化器在做索引选择的时候更复杂,更加难以优化。
六、存储空间
数据库中的 一行记录 在最终 磁盘文件 中也是以 行 的方式来存储的,对于 InnoDB 来说,有 4 种行存储格式:REDUNDANT、 COMPACT、 DYNAMIC 和 COMPRESSED。
InnoDB 的默认行存储格式是 COMPACT,存储格式如下所示,虚线部分代表可能不一定会存在。

- 变长字段长度列表:有多个字段则以逆序存储,存储格式是
16进制,如果没有变长字段就不需要这一部分了。 NULL值列表:用来存储我们记录中值为NULL的情况,如果存在多个NULL值那么也是逆序存储,并且必须是8bit的整数倍,如果不够8bit, 则高位补0。1代表是NULL,0代表不是NULL。如果都是NOT NULL那么这个就不存在了。ROW_ID: 一行记录的唯一标志,没有指定主键的时候自动生成的ROW_ID作为主键。TRX_ID: 事务ID。ROLL_PRT: 回滚指针。- 最后就是每列的值。
为了说明清楚这个存储格式的问题,再建张表 t_demo 来测试,这张表只有 FstrOne 字段是 NOT NULL, 其他都是可以为 NULL 的。
-- mysql>
show create table t_demo;
-- +--------|---------------------------------------+
-- | Table | CreateTable |
-- +--------|---------------------------------------+
-- | t_demo | CREATE TABLE `t_demo` (
-- `FuiId` int(11) unsigned NOT NULL AUTO_INCREMENT,
-- `FstrOne` varchar(255) NOT NULL DEFAULT '',
-- `FstrTwo` varchar(255) DEFAULT NULL,
-- `FstrThree` varchar(255) DEFAULT NULL,
-- `FstrFour` varchar(255) DEFAULT NULL,
-- PRIMARY KEY (`FuiId`)
-- ) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
-- +--------|---------------------------------------+
-- 1 row in set (0.01 sec)
select * from t_demo;
-- +-------+---------+---------+-----------+----------+
-- | FuiId | FstrOne | FstrTwo | FstrThree | FstrFour |
-- +-------+---------+---------+-----------+----------+
-- | 1 | a | NULL | bb | NULL |
-- +-------+---------+---------+-----------+----------+
-- 1 row in set (0.00 sec)- 可变字段长度列表:
FstrOne和FstrThree字段值长度分别为 1 和 2,所以长度转换为 16 进制是0x01 0x02,逆序之后就是0x02 0x01。 NULL值列表:因为存在允许为 NULL 的列,所以FstrTwo,FstrThree,FstrFour分别为0,1,0, 逆序之后,同时高位补0满8位,结果是00000010。
其他字段我们暂时不管他,第一条记录的结果就是,当然这里我们就不考虑编码之后的结果了。
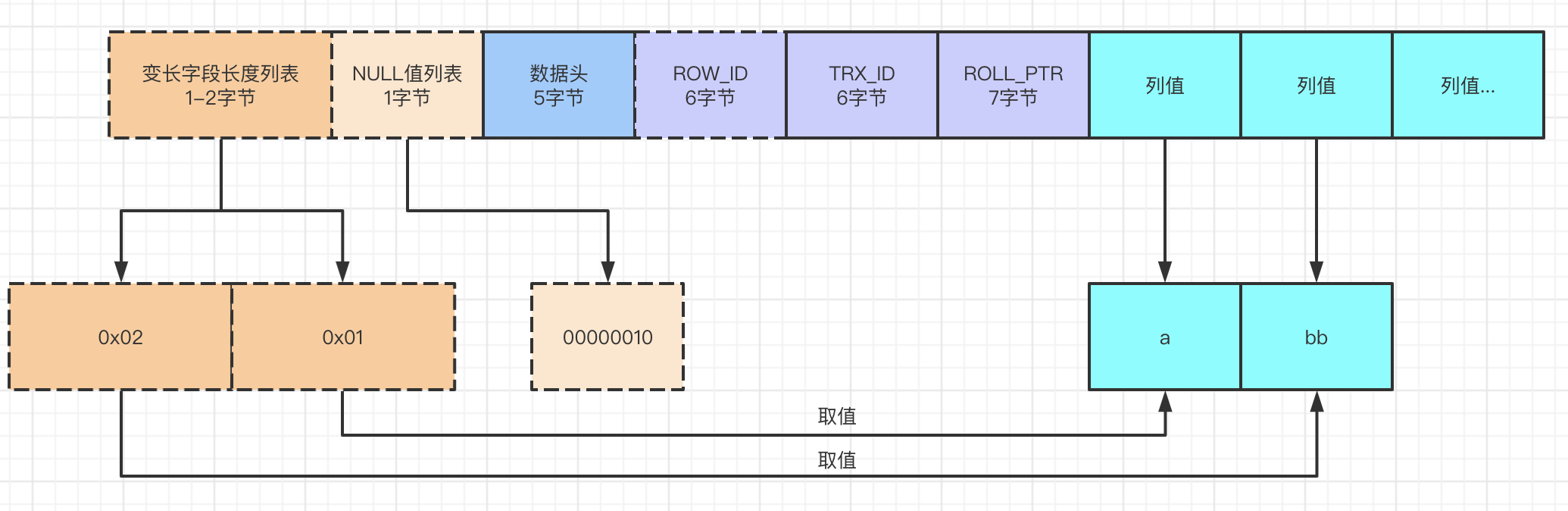
这样就是一个完整的数据行数据的格式。
虽然我们发现 NULL 本身并不会占用存储空间,但是如果存在 NULL 的话就会多占用一个字节的标志位的空间。
七、总结
综上,不管是基于规范还是为了避免踩坑,表字段都建议设置 NOT NULL。